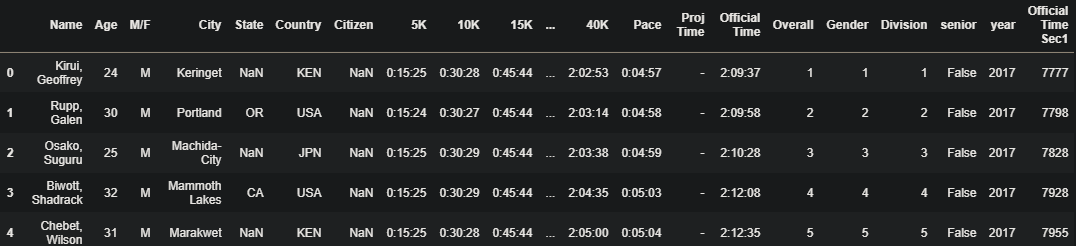
#시간 데이터가 object 형태이고, 이를 시간 형태로 바꾸고 초 단위로 바꾸기 # 방법1. 사용자 정의 함수 : 시간을 정제하는 함수 만들기 >>> def to_second(record): hms = record.str.split(':', n=2, expand=True) #n=2, expand=True : 2개의 컬럼을 추가 second = hms[0].astype(int)*3600 + hms[1].astype(int)*60 + hms[2].astype(int) return second >>> marathon_2017_cleaned['Official Time'].str.split(':', n=2, expand=True) >>> marathon_2017_cleaned.head() >>> marathon_2017_cleaned['Official Time Sec1'] = to_second(marathon_2017_cleaned['Official Time']) >>> marathon_2017_cleaned.head() # 방법2. pandas 내장 함수 이용 : .to_timedelta() >>> pd.to_timedelta(marathon_2017_cleaned['Official Time']) # 초 단위로 바꿔준(astype('m8[s]')) 후 int type으로 바꿔주기(astype(np.int64)) # 'm8[s] >>> s:초 / m:분 / h시간' >>> marathon_2017_cleaned['Official Time Sec2'] = pd.to_timedelta(marathon_2017_cleaned['Official Time']).astype('m8[s]').astype(np.int64) >>> marathon_2017_cleaned.head()
▶ 데이터 저장
# csv : 빠름, 용량 적음, 한글 꺠질 우려가 있음. # xlsx : 느림, 한글은 xlsx가 좋음
# csv로 저장 >>> marathon_2017_cleaned.to_csv('./data_boston/marathon_2017.csv', index=None, header=True)
# xlsx로 저장 >>> marathon_2017_cleaned.to_excel('./data_boston/marathon_2017.xlsx', index=None, header=True)